




MBC 제3노조 "20년 전 동의를 근거로 AI 학습…'정신을 도둑 맞았다'"
입력 2024.10.16 13:48
수정 2024.10.16 13:48
MBC노동조합(제3노조), 16일 성명 발표
 ⓒ
ⓒ
네이버는 아직도 자신이 무엇을 했는지 정신을 못차린 것 같다.
AI가 없는 시절 받은 개인정보 (서비스 이력) 이용동의를 가지고 개인의 수십년 기사조회 이력을 샅샅이 딥러닝해 ‘정신’을 스캐닝하는 것을 ‘합법’이라고 오판하는 것 같다.
이런 준법의식으로 대한민국의 미디어 플랫폼을 독점한다면 너무도 위험성이 크다.
지금부터라도 투명한 공개와 대중적인 검증, 그리고 새로운 개인정보 이용동의에 나서야 마땅함에도 전혀 반성의 모습이 보이지 않는다.
네이버의 기사이력 조회 행태에 대한 기사가 나가자 댓글창에는 “오싹하다” “개인 정치성향 파악할 것 같다”는 경계의 글들이 올라오고 있다.
 네이버 사옥.ⓒ연합뉴스
네이버 사옥.ⓒ연합뉴스
▣ 네이버 딥러닝을 통해 나의 기사조회 이력이 ‘전면 스캔된다’
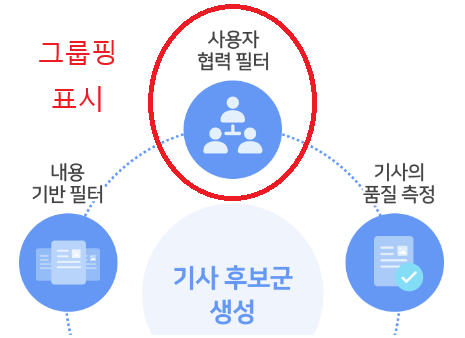
네이버는 CBF (Content-Based Filtering)를 통해 이용자 개인이 과거 조회한 기사를 인공지능이 딥러닝한다고 소개하고 있다. 이용자가 조회한 기사에 등장한 단어(키워드)와 그 기사의 중요도를 차별화하는 작업이 1단계이고, 중요도가 높은 단어나 관련성이 높은 기사를 선별하는 것이 2단계 작업이다.
이러한 작업들은 인공지능에 설정값을 넣어서 수행하게 되고 인공지능의 학습과정의 중요한 피드백은 결국 네이버가 조정해주면서 진행하게 된다.
이를 더 구체화하면 이렇다.
특정 이용자가 한동훈 대표와 관련된 기사와 이재명 대표의 재판 관련 기사를 집중적으로 조회해 왔다고 했을 때 이러한 기사에 자주 등장하는 키워드를 뽑게 된다.
예를 들면, 한동훈 대표와 관련하여서는 ‘용산’ ‘독대’ ‘격차 해소’ 등의 키워드가 나올 수 있고, 이재명 대표와 관련해서는 ‘대장동’ ‘특검’ ‘전국민 25만원’ 등의 키워드가 나올 수 있다.
그러면 이러한 키워드들이 많이 등장하는 기사나 키워드들과 관련성이 높은 기사를 인공지능이 선별하고 추천해 주는 것이다.
이러한 작업은 결국 개인의 기사 취향을 특정하는 것이고 다시 말해 정치적 성향을 특정하는 것이다.
이러한 데이터가 네이버 인공지능 안에 고스란히 개인별로 저장되어 있다면 얼마나 섬뜩한 일인가? 이러한 일들은 충분한 설명 후에 개인별로 동의를 받는 작업이 반드시 필요하다. 20년전 동의를 활용한다는 네이버의 설명은 불법을 자인하는 일이다.
2024.10.16.
MBC노동조합 (제3노조)




